著者:Tarotan (@BluesNoNo: 小野裕亮)
同ブログにおける記事の責任はすべて筆者個人だけにあり,所属企業は一切の責任を負いません.
1. はじめに
1.1 このブログ記事を書くきっかけ
このブログ記事では,単純対応分析(simple correspondence analysis)で使われているいくつかの同時布置図を紹介します.
このブログ記事を書くきっかけは,データポエマー[,-5]さん(@bob3bob3)の以下の記事です.
データポエマー[,-5]さん(@bob3bob3)による上記の記事は,松本健太郎さん(@matsuken0716)による以下のブログ記事にやや反論する形式で書かれています.
1.2 このブログ記事の構成
このブログ記事の構成は,次のとおりです.
第2節では,単純対応分析のような記述的手法に関しては,自分や他人が結果を誤解すると思うのであれば,該当の手法を使わないほうがいいとの個人的な意見を述べます.
第3節では,単純対応分析の結果を図示する方法として,同時布置図以外のグラフを紹介します.
第4節では,単純対応分析の同時布置図を描くときに,どの座標を用いるかによって,グラフから読み取れる情報が異なってくることを紹介します.まず,単純対応分析の座標として,標準座標と主座標があることを紹介します.そして,フレンチプロット・非対称バイプロット・対称バイプロットといった同時布置図を紹介します.また,それ以外にも,列と行の「距離」を解釈できるようにするために,多重対応分析を利用する方法を紹介します.
第5節は,まとまです.
1.3 お断り
なお,私自身は経済的には統計分析でご飯を食べていますが,実データを分析したり,数理的な理論の発展に貢献したり,応用的な手法を考えたりしているわけではありません.
このブログ記事は,前々項(1.1)で紹介した2つのブログ記事(データポエマー[,-5]さん(@bob3bob3)と松本健太郎さん(@matsuken0716)のブログ記事)に関して,技術的なことをほんの少し補足説明しているだけであり,何かしらの新たな視点を提示するわけではありません.
このブログ記事でも,松本健太郎さんによる上記のブログ記事で使われている仮想データを用いています.ただし,実際の商品名が使われていた箇所は,A,B,C,D,Eと置換しました.
2. そもそも単純対応分析が必要なのか?
2.1 記述統計は難しい
そもそも,記述的な統計手法においては,自分や相手が誤解する可能性が高いのであれば,その統計手法を用いるべきではないと私は思います.
極論・暴論かもしれませんが,予測に主眼を置いた回帰分析などでは,手法そのものがまったくのブラックボックスであり,かつ,手法やアルゴリズムを誤解していたとしても,検証データや将来データでの予測精度が保持されていれば,予測に関してはまあ妥当な結果でしょう.
また,因子分析や構造方程式モデルなど,特定の確率的な統計モデルに基づく手法も,(検証データでの)適合度統計量や情報量規準を抑えておけば,細かい部分はブラックボックスにしても,半ば機械的に利用することができるでしょう(現実には,ある程度の枠組みを知っていないと,いろいろと難しいでしょうが).
記述的な統計手法では,特定の統計モデルを仮定しません.そのため,モデルの予測精度・適合度統計量・情報量規準などの分かりやすい指標が算出されません.記述的な統計手法では,提示された結果に基づいて,ユーザーがいろいろと自分で解釈する必要があります.
以上のような特徴が記述的な統計手法にはあると個人的には思います.そのため,自分が分からないものや誤解してしまう可能性が高い記述的な統計手法は,予測モデリングや統計モデルに基づく推測のとき以上に,なるべく避けるようにしたほうがいいと私は思います.
2.1 単純対応分析は基本的には記述的な手法である
単純対応分析も,基本的には,記述的な統計手法です(Goodmanのように,対数線形モデルなどと対比させながら一種の統計モデルとして捉える立場もありますが,こここではそのような議論は無視します).何かしらの特定の統計的モデルに基づいているわけではありません.単純対応分析では,自分の解釈や利用方法が「正しい」かどうかが,何かしらの単純な指標で保障されるわけではありません.
2. 単純対応分析を行ったら同時布置図を描く必要があるのか? そもそも単純対応分析は必要なのか?
2.1 同時付置図の欠点
2.1.1 同時付置図の直感的理解は,たびたび間違える
単純対応分析を行った場合,その結果を示すのに同時布置図がよく描かれます.同時布置図としては,行座標に対しても,列座標に対しても,主座標を用いたフレンチプロットがよく描かれます(「主座標」や「フレンチプロット」については後述します).
多くの実用的な場面において,同時布置図は必要なのでしょうか? もっと遡って,多くの実用的な場面において,そもそも単純対応分析は必要なのでしょうか?
私は,特にカテゴリー数が少ない場合には,同時布置図は必要ないし,そして(理解できていないのであれば)無理して単純対応分析を用いる必要はないと考えます.
下図は,前述の松本健太郎さんによるブログ記事で取り上げられていた仮想データのフレンチプロットです.
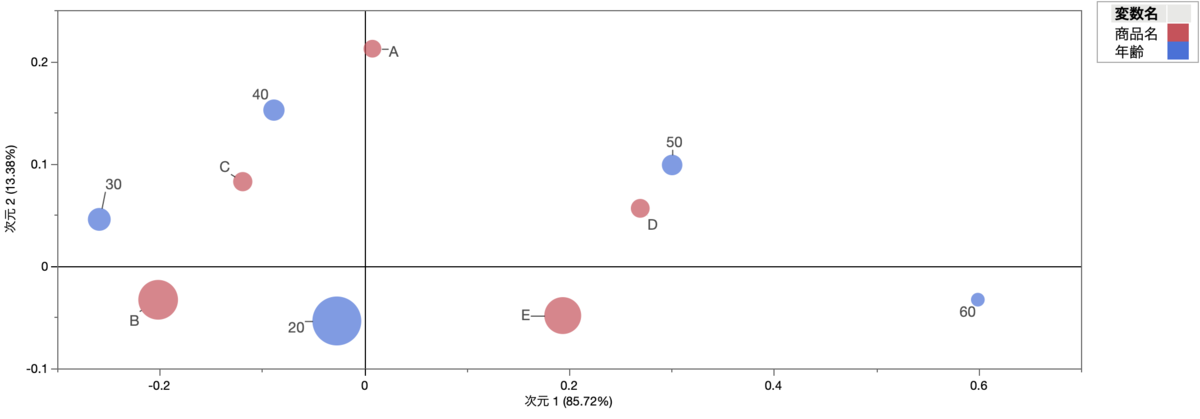 このグラフにおいて,「50歳と商品Dは距離が近い」です.しかし,たとえ距離が近くても,次のことはまったく言えません(実際のデータでもそうなっていません).
このグラフにおいて,「50歳と商品Dは距離が近い」です.しかし,たとえ距離が近くても,次のことはまったく言えません(実際のデータでもそうなっていません).
- 「50歳代で,かつ,商品Dを多く購入している人の人数は多い.」
- 「50歳代の人は,他の商品よりも,商品Dを多く購入している.」
- 「商品Dを購入している人のなかでは,50歳代が最も多い」
次のことは,かなりのベテランユーザーが注意深く見れば,少し言えるかもしれません(しかし,後述するように,厳密には,フレンチプロットではなく,非対称バイプロットでなければ,下記のことは見た目からは分かりません).
- 「50歳代(および60歳代)は,他の年齢層と比べて,商品D(および商品E)を購入する割合が相対的に高い」
これを見るには,まず,原点から各点までのベクトルの内積を見る必要があります.
そして,フレンチプロットにおいては(強引に)内積を見るには,各主軸での分散(慣性)に注意する必要があります(繰り返しになりますが,このような内積による理解は,厳密には非対称バイプロットを用いる必要があります).
2.1.2 そもそも,同時付置図は近似でしかない
さらに,そもそも,同時布置図は,主成分分析と同じように,近似でしかありません.たとえ,同時布置図が正確な平面地図であったとしても,それは,あくまで2次元で近似したものに過ぎません.現実世界でも,たとえ同じ緯度・経度であっても,スカイツリーの展望エリアにいるのと地上にいるのでは,意味的には大きな違いがあるでしょう.2次元の壁に映った影が蟹や狐であったとしても,3次元での手の形は別物でしょう.2次元の近似でしかないのだから,どんなに巧妙な手法で同時布置図を描いたとしても,それはより高次元での分布の近似でしかありません.
2.1.3 同時付置図はカテゴリー数が少ないときはあまり役立たない
上記のように考えると,(単純対応分析を知らない人には)誤解が生じやすいですし,さらに,そもそも2次元の近似でしかないので厳密性も欠きます.そのため,カテゴリー数が少ないのであれば,わざわざ同時付置図を描く必要はないと思います.
2.2 同時付置図の代わりになるかもしれないグラフ
2.2.1 カテゴリーの表示順序を入れ替えたグラフ
同時付置図の代わりに,ここでは次の3つのグラフを紹介します.これらのグラフでは,単純対応分析の結果のうち,第1次元目の座標しか使っていません.いずれのグラフも,単純対応分析の第1次元の座標に基づき,カテゴリーを並び替えています.
これらのグラフは,いずれも大津(pp.154-155)で紹介されているアイデアに基づいています(そのアイデアでは,「Jacques Bertinの可換マトリックス表示法[...] に対応分析によて得られたスコアを利用」(大津 2003, p.154)しています).
2.2.2 その1:モザイク図
1つ目のグラフは,下に示すようなモザイク図です.
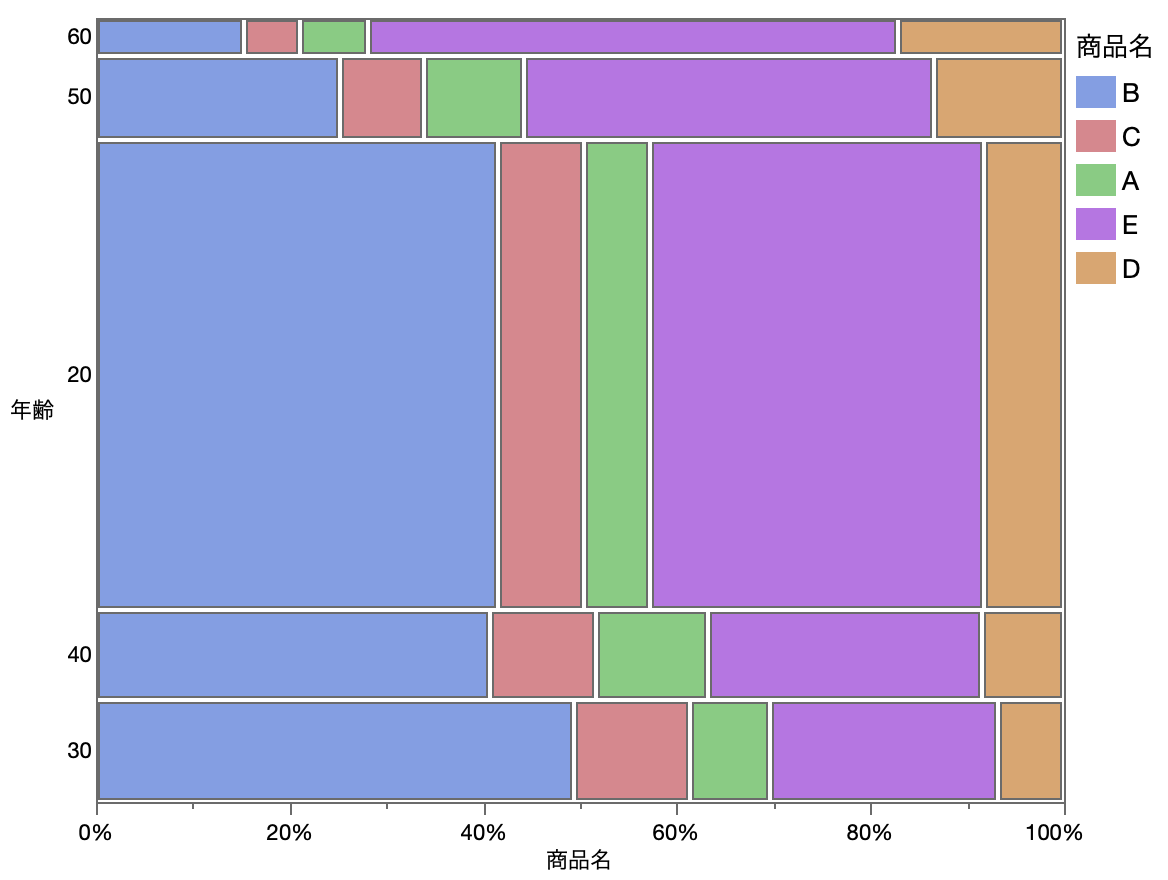
これは通常のモザイク図ですが,単純対応分析の1次元目の座標にもとづいて各カテゴリーを並び替えています.
- 50歳代で,最も購入が多いのは(商品Dではなく)商品Eであることがすぐにわかります.
- また,購入人数で言えば,(各長方形の面積を見ることにより)商品Dを最も購入しているのは20歳代であることがわかります.
(...もちろん,モザイク図の見方を知っておく必要はありますが....)
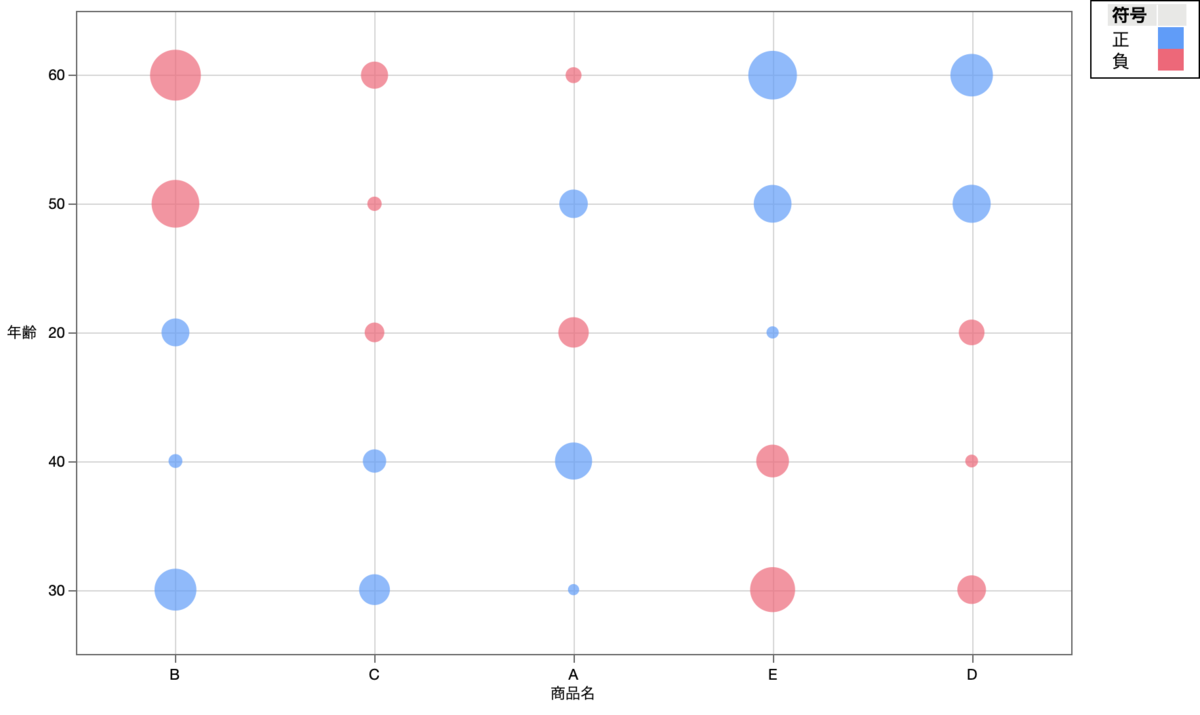
2.2.3 その2:度数表のバブルプロット
2つ目のグラフは,下図のように,度数表をグラフにしたものです.円の大きさが度数の大きさを示しています.なお,ここでも,各カテゴリーを単純対応分析の1次元目で並び替えています.
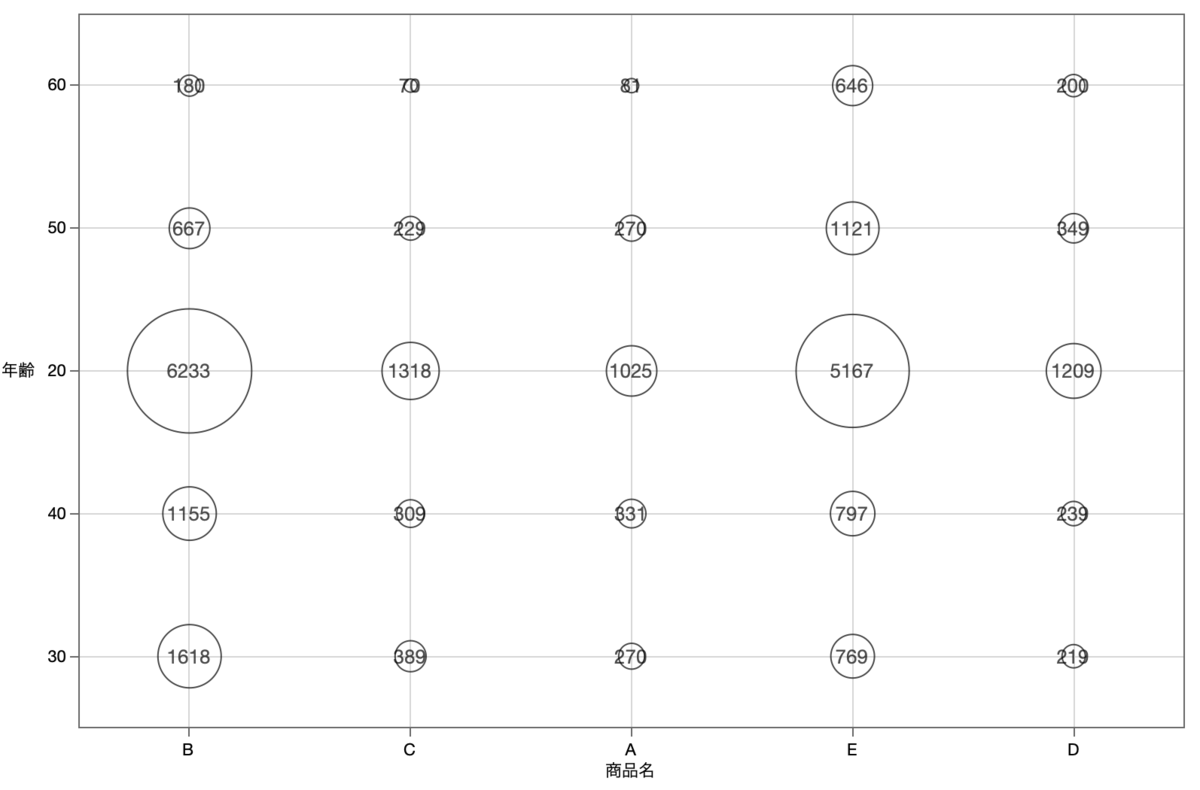
「商品Dを購入している年齢層は,人数で見ると20歳代が最も多い」ことが,先ほどのモザイク図よりもすぐに分かります.
2.2.4 その3:偏差のバブルプロット
3つ目のグラフは,やや難しいもので,おそらく初等統計学を学んだ人にしか意味が分からないグラフとなります.下図では,上図のように度数をプロットするのではなく,<偏差を期待値で割ったもの>をプロットしています.
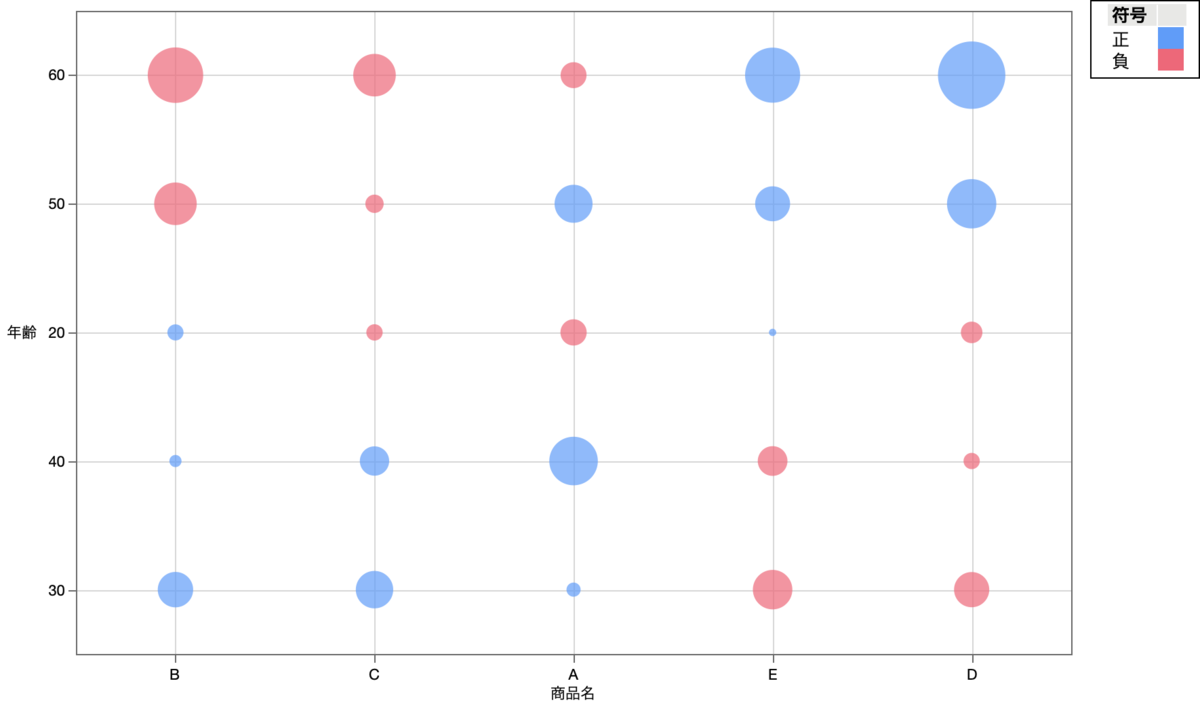
このグラフは,分かる人にしか分からないグラフでしょう.しかし,分かる人が見れば,相対的割合の大小がどうなっているかが一目で分かります.
グラフからは,商品D(と商品E)では,<偏差を期待値で割ったもの>が,50代(と60代)で大きくなっていることがわかります.このことから,50代(と60代)にて商品D(と商品E)を選んでいる割合が,他の年齢層と相対的に比べた場合には高いことが一目でわかります.
少なくとも初等統計学では,<偏差を期待値で割ったもの>ではなく,<偏差を期待値の平方根で割ったもの>であるがよく使われます.<偏差を期待値の平方根で割ったもの>は,「Pearson残差」などと呼ばれています.Pearson残差の平方和は, 表の
表の 統計量となります.Pearson残差をプロットしたものは下図の通りです.
統計量となります.Pearson残差をプロットしたものは下図の通りです.
2.3 カテゴリー数が少ないのであれば,わざわざ単純対応分析をする必要はないと思う
前項での3つのグラフでは,カテゴリーを並び替えるのに,単純対応分析を利用しました.単純対応分析における1次元目の座標によって,カテゴリーをソートしました.しかし,カテゴリー数が少ないのであれば,単純対応分析を使わず,手作業でソートしても,それほど手間ではないと思われます.
よって,カテゴリー数が少ないのであれば,同時付置図を描く必要ななく,上記のようなグラフを描いたので十分だろうし,その際に単純対応分析を行わなくても,手作業でカテゴリーを並び替えたので十分ではないかと個人的には思います.
3. さまざまな座標,さまざまな解釈
3.1 この節の構成
この節では,まず,標準座標と主座標について紹介し,それらを行列表記を用いながら簡単に説明します.続いて,フレンチプロット・非対称バイプロット・対称バイプロットといった同時布置図を紹介します.また,列と行の「距離」を解釈できるようにするために,多重対応分析を利用する方法を紹介します.
3.2 標準座標と主座標
単純対応分析(や主成分分析,多重対応分析)では,いくつかの種類の座標があります.有名なものには,主座標(principal coordinate)と標準座標(standard coordinate)があります.
主座標では,各次元での主座標の分散が固有値と等しくなっています.この性質から,固有値(主座標の分散)は,物理学の力学からの用語である「慣性モーメント」を援用して「慣性」と呼ばれることがあります.
一方,標準座標では,分散が1に標準化されています.
単純対応分析を<多次元の空間上に散らばっている点を低次元の空間(たとえば2次元)へ射影する手法>と考えた場合,その視点から自然に導かれる座標は主座標でしょう.
一方,数量化Ⅲ類のように,<相関係数を最大化するスコアを求める>というような枠組みを考えた場合には,その視点から自然に導かれる座標は標準座標でしょう.
3.3 標準座標と主座標の行列表記
3.3.1 単純対応分析の行列表記
単純対応分析は,次のような特異値分解から算出することができます.

上式において,各記号の意味は次のとおりです.
 は,各セルの度数を総度数で割ったものを要素とする行列です(
は,各セルの度数を総度数で割ったものを要素とする行列です( は度数表の行数,
は度数表の行数, は度数表の列数).
は度数表の列数). は,行和および列和を固定し,かつ,行と列が独立であるとの仮定から算出されるの期待値です.行の周辺割合を要素とする
は,行和および列和を固定し,かつ,行と列が独立であるとの仮定から算出されるの期待値です.行の周辺割合を要素とする のベクトルを
のベクトルを ,列の周辺割合を要素とする
,列の周辺割合を要素とする のベクトルを
のベクトルを とすると,
とすると, です.
です. は,を対角要素とする
は,を対角要素とする の対角行列です.
の対角行列です. は,を対角要素とする
は,を対角要素とする の対角行列です.
の対角行列です.- 右辺は,左辺の行列
 を特異値分解したものです.以下で,
を特異値分解したものです.以下で, を左辺の行列がもつ次元とします.実用上の多くの場面で
を左辺の行列がもつ次元とします.実用上の多くの場面で  となっています.
となっています.
 は,左特異ベクトルを含む
は,左特異ベクトルを含む  の列直交行列です(ここで列直交行列とは,
の列直交行列です(ここで列直交行列とは, となっている行列を指します.
となっている行列を指します. は
は の単位行列です).
の単位行列です). は,右特異ベクトルを含む
は,右特異ベクトルを含む  の列直交行列です(ここで列直交行列とは,
の列直交行列です(ここで列直交行列とは, となっている行列を指します).
となっている行列を指します). は,特異値を対角要素にもつの対角行列です.特異値は,固有値(慣性; 主座標の分散)の正の平方根です.
は,特異値を対角要素にもつの対角行列です.特異値は,固有値(慣性; 主座標の分散)の正の平方根です.
なお,左辺  の各要素は,Pearson残差を総度数の平方根(
の各要素は,Pearson残差を総度数の平方根( )で割ったものです.よって,それらの各要素の平方和は,
)で割ったものです.よって,それらの各要素の平方和は, 統計量を
統計量を で割ったもの,すなわち,ファイ係数の2乗となっています.
で割ったもの,すなわち,ファイ係数の2乗となっています.
3.3.2 主座標の行列表記
前目(3.3.1)での記号を用いると,主座標は次のように表されます.
- 行の主座標:

- 列の主座標:

3.3.3 標準座標の行列表記
前々目(3.3.1)での記号を用いると,標準座標は次のように表されます.
- 行の標準座標:

- 列の標準座標:

前目(3.3.2)で記した主座標では,各列の分散が各次元の固有値と一致します.一方,標準座標では,いずれの次元でも各列の分散は になっています.
になっています.
3.4 フレンチプロット
行の座標に対しても,列の座標に対しても,両方とも主座標を採用して,かつ,1枚のプロットに示したグラフは,「フレンチプロット」・「対称プロット」・「Benzécriプロット」などと呼ばれています.
主座標を用いた場合,プロットにおけるそれらの点のあいだのユークリッド距離は,カイ2乗距離(を近似したもの)を表しています.行に対して,主座標をプロットすれば,そのプロットでのある列Aの点と別の列Bの点とのユークリッド距離は,その列Aと列Bとのカイ2乗距離(を近似したもの)を表すことになります.なお,ここで「近似」と述べているのは,たとえば平面にプロットした場合は,2次元までの情報しか使っていないので,元のカイ2乗距離を近似したものにすぎないからです.
主座標がカイ2乗距離を表現することを,行列表記で荒く説明しましょう.
行の主座標を とします.
とします. ですので, 特異値分解の結果であるの両辺に
ですので, 特異値分解の結果であるの両辺に をかけると,
をかけると, となります.
となります.
 は,同時割合(から期待割合を引いたもの)を行周辺割合で割っています.よって,各行で計算された条件付き割合(から期待割合を引いたもの)となっています.
は,同時割合(から期待割合を引いたもの)を行周辺割合で割っています.よって,各行で計算された条件付き割合(から期待割合を引いたもの)となっています. という条件付き割合は,「行プロファイル」と呼ばれています.
という条件付き割合は,「行プロファイル」と呼ばれています.
その行プロファイル(から期待割合を引いたもの)の各列は,列周辺割合の平方根で標準化されています(通常の主成分分析では,標準偏差で標準することが多いですが,対応分析では,このように列周辺割合で標準化しています.また,単純対応分析では,各行は,行周辺和だけの度数(質量,重み)があるとして計算されます.通常の主成分分析は,各行の度数は1とされてることが多いです.さらに,通常の主成分分析では,各列は列平均が引かれることが多いです).
行列 における,第
における,第 行目と第
行目と第 行目のユークリッド距離は,第行目のプロファイルと第行目の行プロファイルの「カイ2乗距離」と呼ばれています.
行目のユークリッド距離は,第行目のプロファイルと第行目の行プロファイルの「カイ2乗距離」と呼ばれています.
また,であり, ]は列直交行列であるため,左辺における行間のユークリッド距離は,行列における行間のユークリッド距離と等しいです.
]は列直交行列であるため,左辺における行間のユークリッド距離は,行列における行間のユークリッド距離と等しいです.
以上は,行プロファイルに関して説明しましたが,列プロファイルについても同じことが言えます.
つまり,行主座標を用いると,そのプロットされた行点のあいだのユークリッド距離は,行プロファイルのカイ2乗距離を近似したものになります.列に関しても同様で,列主座標を用いると,そのプロットされた列点のあいだのユークリッド距離は,列プロファイルのカイ2乗距離を近似したものになります.
フレンチプロットは,行に対しても,列に対しても,主座標をプロットしたものでした.そのため,行点と行点のあいだの距離は上記のように解釈できます.同様に,列点と列点のあいだの距離も上記のように解釈できます.しかし,行点と列点のあいだの距離は,(基本的には)解釈できません.
3.5 非対称バイプロット
3.5.1 記号
この項では,主座標および標準座標を次のように表記します.
- 行の主座標を列に含んだ行列を,

- 列の主座標を列に含んだ行列を,

- 行の標準座標を列に含んだ行列を,

- 列の標準座標を列に含んだ行列を,

3.5.2 非対称バイプロット
特異値分解した結果は,でしたので,次のような関係が成立します.

左辺が 乗ではなく
乗ではなく 乗になっている点に注意してください.この式より,次の2つの内積が,<偏差を期待値で割ったもの>と等しくなることが分かります.
乗になっている点に注意してください.この式より,次の2つの内積が,<偏差を期待値で割ったもの>と等しくなることが分かります.
- 行の主座標と,列の標準座標の内積
- 行の標準座標と,列の主座標の内積
このアイデアに基づき,上記のような非対称な形式(一方が主座標,もう一方が標準座標)で描いたバイプロットを,「非対称バイプロット」などと呼びます.
前の式の両辺に と
と をかけると,次のように変形できます.
をかけると,次のように変形できます.

この式より,次の2つの重み付き内積が,<偏差を期待値の平方根で割ったもの>,つまり,Pearson残差(を総度数の平方根で割ったもの)と等しくなることが分かります.
- 行の主座標と,列の標準座標の,周辺割合の平方根で重み付けた重み付き内積
- 行の標準座標と,列の主座標の,周辺割合の平方根で重み付けた重み付き内積
周辺割合は,「重み」や「質量」と呼ばれています.ある行の周辺割合はの該当する対角要素であり,ある列の周辺割合はの該当する対角要素です.
この重み付き内積には,周辺割合(重み,質量)が関わってくるので,プロットから読み取るには,周辺割合の情報がプロットに描かれている必要があります.周辺割合の情報をプロットに描く場合には,円の大きさで描くことが多いと思われます.
わざわざプロットから周辺割合を読み取るのは面倒だが,内積の解釈としては,Pearson残差を見たい場合には,次のような座標のいずれかを用いることも考えられます.
- 行座標として
 ,列座標として.
,列座標として.
- 行座標として,列座標として
 .
.
この座標は,たとえばGower et al.(2011, pp.290-291)で紹介されています.
3.5.3 非対称バイプロットにおいて,距離によって行と列との関係を解釈する場合
一方に主座標,もう一方に標準座標を用いる非対称バイプロットは,前目(3.5.2)で述べたように内積によって,行と列との関係について,ある側面を知ることができます.その非対称バイプロットでは,そのような内積だけではなく,距離によって,行と列との関係についての特定の側面を解釈することもできます.
列標準座標は,<該当の列だけを100%としてそれ以外のすべての列を0%とした行プロファイルの行主座標>と一致します.同様に,行標準座標は,<該当の行だけを100%としてそれ以外のすべての列を0%とした列プロファイルの列主座標>と一致します.
この性質を考えれば,<標準座標で表されたある列点と,主座標で表されたある行点との距離>は,<該当のその列だけを100%としてそれ以外を0%とした行プロファイルと,該当の行の行プロファイルとのカイ2乗距離>を表すことになります.
同様に,<標準座標で表されたある行点と,主座標で表されたある列点との距離>は,<該当のその行だけを100%としてそれ以外を0%とした列プロファイルと,該当の列の列プロファイルとのカイ2乗距離>を表すことになります.
3.5.4 フレンチプロットと非対称バイプロットの相違点
先ほどのフレンチプロットとは異なり,非対称バイプロットでは,上記のような意味で,行と列との関係におけるある側面を見ることができます.また,非対称バイプロットのうち,主座標で描かれているほうは,カイ2錠距離(の近似)として解釈できます.しかし,標準座標で描かれているもの同士の距離や内積は(基本的には)解釈できません.
3.5.5 非対称バイプロットの実用上の欠点
非対称バイプロットは,実用ではあまり使われていないのではないかと思います.その理由の1つが,「見栄えが悪くなる」からです.
特に,各カテゴリーにほどよく度数が分布している場合,非対称バイプロットは,主座標で描いている点が中心にゴチャゴチャに固まったグラフになります.下図は,松本健太郎さん(@matsuken0716)のブログ記事での仮想データをもとに描いた非対称バイプロットです.

非対称バイプロットがこのような中心にグジャッと固まったグラフになりやすい理由は,標準座標が,もう一方のプロファイルで100%としたときの主座標になることを考慮すると,直感的に理解できるでしょう.
3.5.6 対称バイプロット
非対称バイプロットは「行点と列点との内積が解釈できる」という利点がありますが,行と列とで扱いが非対称となっています.そこで,「行点と列点との内積が解釈できる」という利点を保持しながら,対称に扱うことが考えられます.
具体的には,
という対称な座標をプロットします.行と列の両方において,主座標と異なり,を 乗している点に注意してください.
乗している点に注意してください.
この非対称バイプロットでは,内積が3.5.2で述べたような解釈が行えます.しかし,列も行もいずれも主座標ではありませんので,行点と行点との距離,および,列点と列点との距離はいずれも(基本的には)解釈できません.
3.6 フレンチプロットでも非対称プロットのように解釈できる?
標準座標にその次元の特異値を掛ければ,主座標となります.標準座標と主座標の違いは,各次元でスケールが違うだけです.つまり,平面にプロットした場合,グラフを横に伸ばしたり,縦に伸ばしたりしただけで,標準座標から主座標へ,もしくは,主座標から標準座標へと変換できます.
標準座標と主座標位はそのようなスケールの違いしかありませんので,もしも,ある次元と別の次元の特異値にそれほど差がないのであれば,標準座標と主座標のいずれでプロットしても見栄えはそれほど変わりません.そのため,もしも,ある次元と別の次元の特異値にそれほど差がないのであれば,非対称プロットで行ったような内積による解釈も行えます.
Gabriel(2002)では,応用の多くの場面では,フレンチプロットであっても内積の近似はそれほど悪くならないし,対称バイプロットであっても行どうしのカイ2乗距離や列どうしのカイ2乗距離の近似はそれほど悪くならないだろうとアドバイスされています.
3.7 行と列の「距離」を解釈するための同時付置図: 多重対応分析の利用
行の第カテゴリーと,列の第 カテゴリーとの距離の2乗を次のように定義するとします.
カテゴリーとの距離の2乗を次のように定義するとします.

分子は,行の第カテゴリーと列の第カテゴリーの2つのうち,いずれか1つのカテゴリーだけが選択されているものの度数です.分母は(選択が独立だとみなしたときの)その期待値です.
この式を用いて,(半ば無理矢理ですが)行どうしのカテゴリーとの距離や,列どうしのカテゴリー と
と の距離も定義することにします.
の距離も定義することにします.
このようにして求められた距離は,行の1変数と列の1変数の2変数をもとに行った多重対応分析でのカイ2乗距離に一致します.この性質より,2変数をもとに単純対応分析ではなく,多重対応分析を行うと,多重対応分析の主座標によってプロットされた行と列のユークリッド距離は,上記した距離を近似することになります.
2変数に対する多重対応分析に対する結果は,それらの一方を行,もう一方を列とした単純対応分析から算出できます.元の単純対応分析の固有値を とすると,最初の
とすると,最初の 次元までは,2変数の多重対応分析の固有値は,
次元までは,2変数の多重対応分析の固有値は,

となります.2変数の多重対応分析の主座標は,元の単純対応分析の標準座標に,この固有値の平方根 をかけたものとなります.
をかけたものとなります.
このように単純対応分析をわざわざ2変量の多重対応分析と見なして,行と列との距離を解釈できるものにするというアイデアは,Carroll, GreenおよびSchafferという3名によって提案されたので(Carroll et al. 1986),「CGSプロット」などと呼ばれています.その後に,同じ雑誌上にて,CGSプロットを否定的に捉えているGreenacreとのあいだで議論がありました.一方,たとえば西里(2019)などはCGSプロットを肯定的に捉えています.
3.8 各種プロットで表現されるもののまとめ
これまでに見てきたように,座標としてどのような種類のものを用いるかによって,プロットから解釈できるものは違います.Gabriel(2002)のp.432に記載されている表を変更・一部省略・一部追加したものを,下表に示します.
|
プロットの種類
|
行座標
|
列座標
|
列と列の距離
|
行と行の距離
|
行と列の内積
|
行と列の距離
|
|
フレンチプロット
|
主座標
|
主座標
|
カイ2乗距離
|
カイ2乗距離
|
△
|
?
|
|
行主座標-非対称
|
主座標
|
標準座標
|
カイ2乗距離
|
×
|
偏差÷期待度数
|
100%からのカイ2乗距離
|
|
列主座標-非対称
|
標準座標
|
主座標
|
×
|
カイ2乗距離
|
偏差÷期待度数
|
100%からのカイ2乗距離
|
|
対称バイプロット
|
標準座標 × 特異値の平方根
|
標準座標 × 特異値の平方根
|
△
|
△
|
偏差÷期待度数
|
?
|
|
CGSプロット
|
多重対応分析の主座標
|
多重対応分析の主座標
|
×
|
×
|
?
|
一緒に選ばれていない度数を期待度数で割ったもの
|
4. 最後に
単純対応分析は記述的手法ですので,自分や相手が誤解する可能性があるなら,使わないほうがいいと思われます.特に,カテゴリー数が少ない場合には,別の表現方法があります.
単純対応分析の座標にはいくつかの種類があり,それによって,同時布置図に描かれるものが異なってきます.
よく使われるフレンチプロットは,「行点と行点のユークリッド距離は,それらの行プロファイルのカイ2乗距離の近似である」および「列点と列点のユークリッド距離は,それらの列プロファイルのカイ2乗距離の近似である」と解釈できます.しかし,行点と列点のあいだの内積や距離は,Gabriel (2002)のような指摘はあるものの,基本的には直ちには解釈ができません.
行と列との関係を見る同時布置図としては,非対称バイプロットとCGSプロットがあります.このうち,非対称バイプロットは,主座標のほうの点が原点周りにギュッと固まってしまうという欠点があります.CGSプロットについては,賛否があります.
参考文献
Carroll, J. D., Green, P. E. and Schaffer. C. M. (1986) Interpoint Distance Comparisons in Correspondence Analysis. 23, 271-280.
Gabriel, K. R. (2002) Goodness of Fit of Biplots and Correspondence Analysis. Biometrika, 89(2), 423-436.
Gower, J., Lubbe, S. and Le Roux,N.(2011) Understanding Biplots. Wiley
西里静彦(2019)回顧:数量化理論とグラフ.データ分析の理論と応用. 8(1),47-57.
大津起夫(2003)社会調査データからの推論:実践的入門.甘利俊一・竹内啓・竹村彰通・伊庭幸人(編)『統計科学のフロンティア10 言語と心理の統計』岩波書店.129-177.
修正履歴
2022-01-18 0:30 初版


